

Trong vài năm trở lại đây, trí tuệ nhân tạo (AI) với các mô hình ngôn ngữ lớn (LLM) đã trở thành tâm điểm. Chúng có khả năng viết văn bản, trả lời câu hỏi và thậm chí giải thích những khái niệm phức tạp. Tuy nhiên, LLM truyền thống có một nhược điểm dễ thấy: chúng không nhớ hay cập nhật tri thức ngoài bộ tham số đã được huấn luyện. Nếu bạn hỏi về một tài liệu nội bộ doanh nghiệp vừa cập nhật hôm qua, một model “thuần” sẽ khó lòng trả lời. Đó là lúc RAG – Retrieval Augmented Generation – xuất hiện như một cách nối dài trí nhớ cho LLM.
Trong bài viết này, Lemon’s Tribe sẽ cùng bạn hiểu rõ RAG là gì, vì sao nó quan trọng, cách triển khai và những lưu ý thực tế khi đưa RAG vào sản phẩm.
- RAG là gì và vì sao cần quan tâm?
- Định nghĩa
- Lý do cần RAG
- Cách thức hoạt động và các bước của RAG
- 1. Thu thập và chuẩn bị dữ liệu – Data ingestion and Parsing
- 2. Chuyển hoá dữ liệu – Data transformation and Embedding
- 3. Xây dựng chỉ mục tìm kiếm – Data indexing
- 4. Truy xuất – Retrieval
- 5. Xây dựng prompt và tạo câu trả lời
- 6. Kiểm soát bảo mật và quyền truy cập
- Điểm mạnh và thách thức của RAG
- Điểm mạnh
- Thách thức và hạn chế
- Các biến thể và cách tối ưu hoá RAG
- Các biến thể của RAG
- Các mô hình RAG ban đầu: RAG‑Sequence và RAG‑Token
- Các biến thể phát triển sau này
- So sánh Agentic RAG và RAG truyền thống
- Chiến lược tối ưu RAG
- Một vài lưu ý khi triển khai RAG
- Các biến thể của RAG
- Tạm kết
- Nguồn tham khảo
RAG là gì và vì sao cần quan tâm?
Định nghĩa
Thuật ngữ RAG – Retrieval Augmented Generation (tạo sinh dựa trên truy xuất tăng cường) xuất phát từ bài nghiên cứu của Patrick Lewis và các cộng sự, trong đó, ý tưởng ban đầu là dùng một mô hình ngôn ngữ được huấn luyện sẵn để sinh văn bản, nhưng kèm theo một hệ thống truy xuất riêng để tìm các tài liệu liên quan nhằm điều kiện hoá đầu ra1. Nói cách khác, RAG là là kỹ thuật mở rộng khả năng của mô hình ngôn ngữ lớn (LLM) bằng cách cho phép chúng tra cứu và truy xuất dữ liệu từ các nguồn bên ngoài, giúp AI đưa ra câu trả lời chính xác, cập nhật và bám sát tài liệu riêng của tổ chức2. Ngoài ra, các tổ chức sử dụng RAG để đưa dữ liệu hiện thời và đặc thù chuyên ngành vào ứng dụng mà không cần fine‑tuning nặng nề3.
Lý do cần RAG
LLM mạnh mẽ nhưng có hai vấn đề cơ bản:
- Kiến thức lỗi thời – mô hình không biết những gì xảy ra sau thời điểm thu thập dữ liệu;
- Xu hướng hallucination (ngáo) – mô hình có thể bịa ra thông tin khi thiếu dữ liệu.4
RAG giải quyết các vấn đề này bằng cách bổ sung một bộ nhớ phi tham số cho LLM. Thay vì nhồi nhét mọi kiến thức vào tham số của mô hình, ta để dữ liệu nằm ngoài và truy xuất khi cần. Điều này giúp cập nhật kiến thức mới đơn giản (chỉ cần cập nhật vector store), giảm chi phí fine‑tune và minh bạch nguồn tham khảo5.
Những use case phù hợp nhất để sử dụng RAG gồm: trợ lý hỏi đáp trên tài liệu nội bộ, enterprise search, hỗ trợ khách hàng, tra cứu chính sách/quy trình, pháp chế, y tế, phân tích báo cáo, và agent cần truy cập knowledge base. Các tài liệu Azure AI Search và Google Agent Search đều đưa RAG/grounded generation như pattern cốt lõi cho chatbot, agent và generative search.6
Cách thức hoạt động và các bước của RAG
Pipeline RAG gồm ba thành phần chính: Ingestion/Indexing – Retrieval – Generation. Tuy nhiên, khi triển khai trong doanh nghiệp, quy trình có thể gồm nhiều bước hơn để đảm bảo dữ liệu phù hợp, bảo mật và hiệu quả. Cụ thể như sau:7

1. Thu thập và chuẩn bị dữ liệu – Data ingestion and Parsing
Mọi ứng dụng RAG đều bắt đầu bằng việc thu thập tài liệu từ nhiều nguồn như tài liệu hướng dẫn, email, cơ sở dữ liệu và API. Quá trình này gọi là data ingestion8. Dữ liệu phải được tích hợp và sau đó được chuyển thành text/cấu trúc có thể tra cứu và truy xuất (parsing). Việc thu thập đầy đủ và liên tục cập nhật là điều kiện tiên quyết: nếu không, hệ thống sẽ trả về kết quả lỗi thời hoặc thiếu thông tin.
2. Chuyển hoá dữ liệu – Data transformation and Embedding
Bước tiếp theo trong mô hình RAG là chuyển hoá dữ liệu (data transformation), trong đó bao gồm việc cắt nhỏ tài liệu (chunking). Chunking là quá trình chia nhỏ tài liệu để phù hợp với giới hạn token của mô hình và đảm bảo thông tin không bị mất khi đưa vào embedding. Có nhiều chiến thuật có thể sử dụng để chunking, ví dụ như chunking theo size (số lượng ký tự hoặc token) cố định – fixed-size chunking, chunking theo dấu cách (dấu phẩy, dấu chấm,…) – recursive chunking, chunking theo ngữ nghĩa (cứ chuyển chủ đề thì chunk) – semantic chunking, chunking theo cấu trúc tự nhiên của nguồn dữ liệu – document-based chunking9.
Sau khi chia nhỏ, mỗi đoạn được chuyển thành vector (embedding) và lưu vào cơ sở dữ liệu vector (vector database). Vector embedding là quá trình chuyển đổi dữ liệu (văn bản, hình ảnh, âm thanh, video…) thành một dãy các con số (vector) để máy tính có thể hiểu và so sánh ý nghĩa của chúng.
Ví dụ:
Giả sử bạn có ảnh một con chó Golden Retriever đang chạy trên bãi cỏ. Con người chúng ta sẽ nhìn thấy:
- Con chó
- Giống Golden Retriever
- Màu vàng
- Đang chạy
- Ngoài trời
- Bãi cỏ xanhModel embedding sẽ trích xuất hàng trăm hoặc hàng nghìn đặc trưng như:
animal = 0.95
dog = 0.98
golden_retriever = 0.92
grass = 0.87
outdoor = 0.91
running = 0.89
yellow = 0.76Sau đó chuyển thành vector:
[0.95, 0.98, 0.92, 0.87, 0.91, 0.89, 0.76, ...]Sau đó, khi người dùng tìm: “Con chó đang chơi ngoài công viên”, hệ thống sẽ tạo embedding cho câu truy vấn đó. Nếu vector của câu truy vấn gần vector của ảnh trên, hệ thống sẽ trả về ảnh đó dù từ khóa “Golden Retriever” không hề xuất hiện.10
Bên cạnh đó, khi tạo embedding, cần lưu ý các yếu tố gồm: chọn mô hình phù hợp, cân bằng giữa kích thước chỉ mục (index) và tốc độ tìm kiếm, cập nhật vector khi dữ liệu thay đổi.
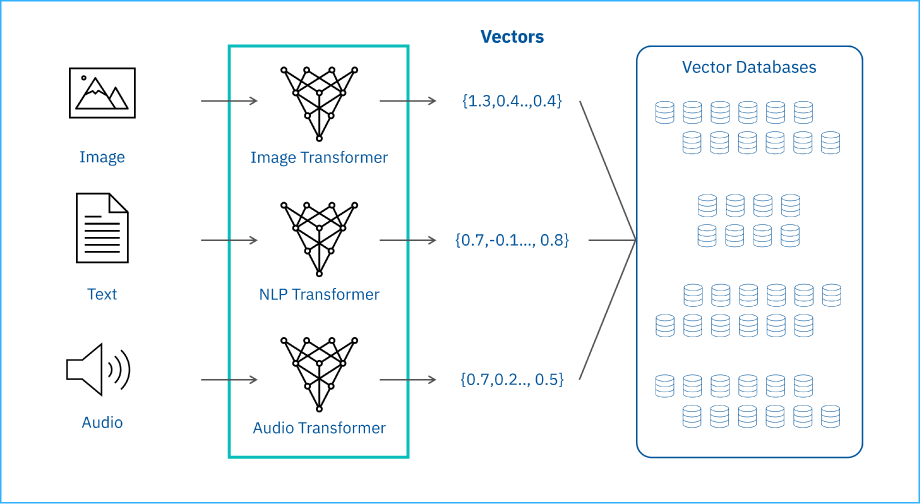
Ngoài ra, để bổ trợ cho việc tìm kiếm được dễ dàng và chính xác hơn, trong quá trình thu thập dữ liệu, các thông tin liên quan đến tài liệu sẽ được trích xuất và được gọi là metadata (ví dụ như một cuốn sách thì sẽ có thông tin về tác giả, năm xuất bản, nhà xuất bản, đề tài,… có thể được trích xuất thành metadata). Sau đó, trong quá trình chunking và embedding, các metadata này sẽ được gắn cùng từng đoạn chunk và lưu vào database.12
3. Xây dựng chỉ mục tìm kiếm – Data indexing
Sau khi xây dựng được database, nhưng nếu data của bạn quá nhiều và không có quy tắc thì việc tìm kiếm dữ liệu sẽ mất rất nhiều thời gian và có khả năng timeout giữa chừng. Chính vì vậy, cũng như các loại database khác, indexing sẽ là cách giúp việc tìm kiếm dữ liệu được dễ dàng hơn rất nhiều. Cụ thể, RAG Engine sẽ tạo ra một chỉ mục (index), thường được gọi là corpus. Chỉ mục này giúp tổ chức và sắp xếp toàn bộ kho tri thức theo cách tối ưu cho việc tìm kiếm và truy xuất thông tin. Có thể hình dung corpus giống như một mục lục cực kỳ chi tiết của một cuốn bách khoa toàn thư khổng lồ. Thay vì phải lật từng trang để tìm câu trả lời, hệ thống chỉ cần tra cứu mục lục để nhanh chóng xác định chính xác phần nội dung liên quan nhất.
Đến đây, chúng ta đã có một kho tri thức được tổ chức dưới dạng vector và sẵn sàng cho việc tìm kiếm. Tuy nhiên, việc lưu trữ dữ liệu mới chỉ giải quyết được một nửa bài toán. Điều thực sự quan trọng là: khi người dùng đặt câu hỏi, làm thế nào để hệ thống tìm đúng những đoạn thông tin liên quan nhất trong hàng nghìn, thậm chí hàng triệu tài liệu đang được lưu trữ? Đó chính là lúc bước Retrieval xuất hiện.
4. Truy xuất – Retrieval
Khi người dùng đặt câu hỏi, hệ thống sẽ bắt đầu tìm kiếm trong cơ sở dữ liệu tài liệu/dữ liệu liên quan để đưa vào xây dựng nội dung phản hồi. Có 2 cách tìm kiếm chính: vector search (tìm kiếm theo vector), và full-text search (tìm kiếm toàn bộ đoạn text). Cụ thể như sau:
- Vector search: Thay vì tìm từ khoá, vector search tìm kiếm dựa trên sự tương đồng ngữ nghĩa. Câu lệnh (prompt) đầu và sẽ được chuyển hoá thành các vector (prompt embedding) và so sánh độ tương đồng giữa vector của câu lệnh với vector của các đoạn đã được cắt nhỏ trong kho dữ liệu. Phương pháp này giúp tìm các đoạn có ý nghĩa tương tự và có khả năng hỗ trợ đa ngôn ngữ.
- Full‑text search (FTS): Hay còn gọi là keyword-based search, là kỹ thuật cho phép tìm kiếm mọi từ hoặc cụm từ trong toàn bộ nội dung của các tài liệu, văn bản hoặc cơ sở dữ liệu. Thay vì tìm kiếm từng từ rời rạc, FTS quét toàn bộ đoạn văn bản dài để đối chiếu và trả về kết quả có độ chính xác cao. Cách tìm kiếm này cho phép phát hiện các đoạn chứa câu trả lời ngay cả khi từ khoá không khớp chính xác. Full‑text search thường kết hợp với các kỹ thuật khác để tận dụng ưu điểm của từng phương pháp.
Ngoài ra, dể cải thiện độ chính xác, Microsoft khuyến nghị sử dụng hybrid search – kết hợp kết quả từ tìm kiếm vector và keyword rồi hợp nhất bằng thuật toán như reciprocal rank fusion. Hybrid search giúp tận dụng cả khả năng hiểu nghĩa và khả năng khớp từ khoá, đặc biệt với các thuật ngữ chuyên ngành hoặc câu hỏi phức tạp.13
5. Xây dựng prompt và tạo câu trả lời
Sau khi có các dữ liệu cần thiết, hệ thống bắt đầu “xào nấu” các nguyên liệu: ghép câu hỏi của người dùng với các đoạn được truy xuất, kèm theo hướng dẫn cho LLM (ví dụ “trả lời dựa trên ngữ cảnh, nếu không biết thì nói ‘không biết’”). Đây là bước quan trọng vì prompt dài, lộn xộn hoặc rò rỉ dữ liệu nhạy cảm sẽ ảnh hưởng chất lượng và bảo mật. Các LLM model sau đó sinh ra câu trả lời dựa trên ngữ cảnh. Trong mô hình agentic retrieval mới, LLM còn tham gia vào việc lập kế hoạch truy vấn và trả về kết quả có cấu trúc (gồm dữ liệu, dẫn nguồn và log truy vấn).14
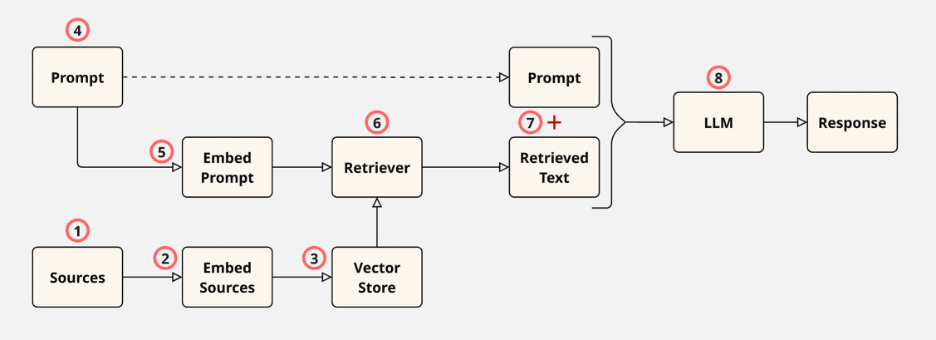
6. Kiểm soát bảo mật và quyền truy cập
Vì RAG truy cập vào dữ liệu nội bộ, kiểm soát quyền truy cập là bắt buộc. RAG cũng cần che mờ dữ liệu nhạy cảm và tuân thủ quy định như GDPR (General Data Protection Regulation).16
Điểm mạnh và thách thức của RAG
Điểm mạnh
Không phải ngẫu nhiên mà RAG trở thành một trong những kiến trúc phổ biến nhất khi xây dựng các ứng dụng AI hiện nay. Điểm hấp dẫn nhất của RAG nằm ở việc nó giúp kết nối sức mạnh suy luận của LLM với những dữ liệu thực tế và luôn thay đổi của doanh nghiệp.
- Lợi ích dễ thấy nhất là khả năng cập nhật kiến thức một cách linh hoạt. Với các mô hình ngôn ngữ truyền thống, mỗi khi muốn bổ sung kiến thức mới, chúng ta thường phải huấn luyện hoặc fine-tune lại mô hình. Quá trình này vừa tốn thời gian vừa tốn chi phí. Trong khi đó, với RAG, kiến thức được lưu trữ bên ngoài mô hình. Khi tài liệu, chính sách hoặc sản phẩm thay đổi, chúng ta chỉ cần cập nhật kho dữ liệu mà không cần động đến mô hình nền tảng. Điều này giúp hệ thống phản ứng nhanh hơn trước những thay đổi liên tục của môi trường kinh doanh.17
- Bên cạnh đó, RAG còn mở ra khả năng cá nhân hóa trải nghiệm người dùng. Thay vì chỉ trả lời dựa trên kiến thức chung đã được huấn luyện từ Internet, AI có thể kết hợp thêm dữ liệu nội bộ như thông tin khách hàng, lịch sử giao dịch hoặc hành vi sử dụng sản phẩm. Nhờ vậy, câu trả lời không chỉ đúng mà còn phù hợp hơn với từng người dùng cụ thể.
- Một ưu điểm khác thường được nhắc đến là tính minh bạch. Khi sử dụng RAG, hệ thống có thể đính kèm nguồn tham khảo hoặc tài liệu gốc được dùng để tạo câu trả lời. Người dùng có thể kiểm chứng thông tin thay vì phải tin tưởng hoàn toàn vào những gì AI nói. Điều này đặc biệt quan trọng trong các lĩnh vực yêu cầu độ chính xác cao như tài chính, y tế hay pháp lý. Đồng thời, việc dựa trên nguồn dữ liệu cụ thể cũng giúp giảm đáng kể hiện tượng hallucination – một trong những vấn đề lớn nhất của các mô hình ngôn ngữ hiện nay.18
- Cuối cùng, RAG có khả năng mở rộng khá tốt. Một hệ thống có thể đồng thời kết nối với nhiều nguồn dữ liệu khác nhau như tài liệu nội bộ, cơ sở dữ liệu, website hay các hệ thống nghiệp vụ. Khi kết hợp với những kỹ thuật mới như Agentic Retrieval, AI thậm chí có thể chủ động lập kế hoạch tìm kiếm và tổng hợp thông tin từ nhiều nguồn khác nhau trước khi đưa ra câu trả lời.19
Thách thức và hạn chế
Mặc dù mang lại nhiều lợi ích, RAG không phải là một giải pháp hoàn hảo. Trên thực tế, việc xây dựng một hệ thống RAG hiệu quả thường khó hơn nhiều so với những gì các sơ đồ kiến trúc đơn giản mô tả.
- Thách thức lớn nhất nằm ở chất lượng dữ liệu. Một nguyên tắc khá quen thuộc trong ngành dữ liệu là “garbage in, garbage out”. Nếu tài liệu bị lỗi thời, thiếu cấu trúc hoặc không được gắn metadata đầy đủ, hệ thống truy xuất rất dễ tìm nhầm thông tin. Khi đó, dù LLM có mạnh đến đâu thì câu trả lời cuối cùng vẫn có thể sai.
- Một vấn đề khác là hiệu năng. So với việc gửi trực tiếp câu hỏi cho LLM, RAG phải thực hiện thêm nhiều bước như tìm kiếm, truy xuất, xếp hạng và xây dựng ngữ cảnh trước khi sinh câu trả lời. Điều này đồng nghĩa với việc hệ thống tốn nhiều tài nguyên hơn và độ trễ cũng cao hơn. Với các ứng dụng yêu cầu phản hồi theo thời gian thực, đây là một yếu tố cần được cân nhắc kỹ.
- Bảo mật cũng là một thách thức không nhỏ. Bởi vì RAG thường truy cập vào dữ liệu nội bộ của doanh nghiệp, hệ thống cần có cơ chế phân quyền, kiểm soát truy cập và che giấu các thông tin nhạy cảm. Nếu thiết kế không cẩn thận, chatbot có thể vô tình truy xuất hoặc tiết lộ những dữ liệu mà người dùng không được phép xem.20
- Ngoài ra, RAG không hoàn toàn loại bỏ được hiện tượng hallucination. Nhiều người lầm tưởng rằng chỉ cần có RAG thì AI sẽ luôn trả lời đúng. Thực tế không phải vậy. Nếu tài liệu được truy xuất không đầy đủ hoặc thiếu ngữ cảnh cần thiết, mô hình vẫn có thể suy diễn và đưa ra câu trả lời sai. Nghiên cứu gần đây của Google thậm chí cho thấy một tài liệu liên quan chưa chắc đã đủ để trả lời câu hỏi; điều quan trọng hơn là ngữ cảnh đó có thực sự chứa đầy đủ thông tin cần thiết hay không.21
- Cuối cùng, triển khai RAG là một bài toán mang tính hệ thống nhiều hơn là một bài toán về mô hình AI. Đội ngũ phát triển cần hiểu về dữ liệu, vector database, embedding, chunking, truy xuất ngữ nghĩa, prompt engineering và cả bảo mật. Đây là lý do nhiều doanh nghiệp nhận ra rằng xây dựng một hệ thống RAG tốt không chỉ là kết nối một LLM với một vector database, mà là cả một quá trình thiết kế và tối ưu liên tục.
Các biến thể và cách tối ưu hoá RAG
Các biến thể của RAG
Nếu nhìn vào sơ đồ trên, RAG có vẻ là một quy trình khá đơn giản: tìm kiếm thông tin, bổ sung ngữ cảnh rồi để LLM tạo câu trả lời. Tuy nhiên, khi triển khai trong thực tế, mọi thứ thường không đơn giản như vậy.
Kho dữ liệu có thể lên đến hàng triệu tài liệu. Người dùng có thể đặt những câu hỏi dài, mơ hồ hoặc đòi hỏi suy luận qua nhiều bước. Trong những trường hợp đó, một lần truy xuất duy nhất chưa chắc đã đủ để tìm được toàn bộ thông tin cần thiết. Đó là lý do cộng đồng AI đã phát triển thêm nhiều biến thể và kỹ thuật tối ưu RAG nhằm cải thiện độ chính xác, giảm chi phí xử lý và nâng cao trải nghiệm người dùng.
Các mô hình RAG ban đầu: RAG‑Sequence và RAG‑Token
Trong nghiên cứu gốc, RAG được chia thành hai cách tiếp cận chính là RAG-Sequence và RAG-Token:
- Với RAG-Sequence, hệ thống sẽ truy xuất một bộ tài liệu liên quan ngay từ đầu và sử dụng cùng bộ ngữ cảnh đó để tạo ra toàn bộ câu trả lời. Có thể hình dung nó giống như việc bạn mở một vài trang tài liệu tham khảo, sau đó đọc xuyên suốt để viết một bài tóm tắt. Vì sử dụng cùng một nguồn thông tin từ đầu đến cuối nên câu trả lời thường có tính liền mạch và nhất quán cao.
- Trong khi đó, RAG-Token linh hoạt hơn. Thay vì chỉ dựa vào một bộ tài liệu cố định, mô hình có thể tham chiếu đến các nguồn thông tin khác nhau trong quá trình tạo câu trả lời. Điều này giống như một người vừa viết vừa liên tục tra cứu thêm tài liệu khi gặp những phần cần bổ sung thông tin. Cách tiếp cận này phù hợp với các câu hỏi phức tạp, đòi hỏi tổng hợp kiến thức từ nhiều nguồn khác nhau, nhưng đổi lại chi phí xử lý cũng cao hơn.
Nói đơn giản, nếu bài toán cần một câu trả lời liền mạch như tóm tắt tài liệu hoặc viết nội dung dài, RAG-Sequence thường là lựa chọn phù hợp. Ngược lại, với các tác vụ hỏi đáp chuyên sâu hoặc cần tổng hợp thông tin từ nhiều nguồn, RAG-Token sẽ phát huy thế mạnh hơn.22
Các biến thể phát triển sau này
Nhận thấy các hạn hết của hai hình thức RAG truyền thống, các chuyên gia đã phát triển thêm một số biến thể khác của RAG, bao gồm:
- Naive RAG là phiên bản cơ bản nhất, thường được mô tả bằng công thức rất đơn giản: Retrieve → Generate. Hệ thống tìm tài liệu trước, sau đó đưa kết quả cho LLM để sinh câu trả lời. Đây là cách tiếp cận dễ triển khai và vẫn đang được sử dụng khá phổ biến. Tuy nhiên, nó thường gặp hai vấn đề lớn là retrieval noise và context fragmentation.
- Để giải quyết những hạn chế này, các hệ thống hiện đại bắt đầu chuyển sang Advanced RAG. Ngoài bước truy xuất thông tin, hệ thống còn bổ sung nhiều cơ chế tối ưu như viết lại câu hỏi, mở rộng truy vấn, tái xếp hạng kết quả tìm kiếm hoặc nén ngữ cảnh trước khi gửi cho LLM. Mục tiêu là giúp mô hình nhận được đúng thông tin cần thiết thay vì một đống tài liệu dài nhưng không thực sự hữu ích.
- Một hướng phát triển khác là Modular RAG. Thay vì xây dựng một pipeline cố định từ đầu đến cuối, hệ thống được chia thành nhiều thành phần độc lập như retriever, vector database, reranker hay router. Nhờ đó, từng thành phần có thể được thay thế hoặc nâng cấp riêng mà không cần thiết kế lại toàn bộ kiến trúc. Điều này khá giống với cách chúng ta xây dựng microservices trong phát triển phần mềm.
- Gần đây hơn, cộng đồng AI bắt đầu nhắc nhiều đến Agentic RAG. Điểm khác biệt lớn nhất là việc truy xuất không còn là một bước cố định trong pipeline nữa. Thay vào đó, chính LLM sẽ đóng vai trò như một người điều phối, tự quyết định nên tìm kiếm ở đâu, tìm kiếm bao nhiêu lần, có cần chia nhỏ câu hỏi hay không, và liệu đã đủ thông tin để trả lời hay chưa.
Nói cách khác, nếu Naive RAG giống như việc mở một cuốn sách và đọc đúng chương được chỉ định, thì Agentic RAG giống như một nhà nghiên cứu thực thụ: liên tục tìm kiếm, đối chiếu, đánh giá rồi mới đưa ra kết luận. Đây cũng là lý do Agentic RAG đang được xem là một trong những hướng phát triển quan trọng của các hệ thống AI Agent hiện nay.23
So sánh Agentic RAG và RAG truyền thống
Một trong những xu hướng mới nhất hiện nay là sự chuyển dịch từ Classic RAG sang Agentic RAG.
- Với Classic RAG, quy trình tương đối đơn giản: người dùng đặt câu hỏi, hệ thống tìm kiếm các tài liệu liên quan, sau đó đưa kết quả cho LLM để tạo câu trả lời. Mô hình này hoạt động khá tốt với các câu hỏi rõ ràng và có phạm vi hẹp.
- Tuy nhiên, không phải câu hỏi nào cũng đơn giản như vậy. Ví dụ, nếu người dùng hỏi: “So sánh ưu nhược điểm giữa RAG, Fine-tuning và MCP khi xây dựng chatbot CSKH cho ứng dụng Ví điện tử.”. Một lần tìm kiếm duy nhất có thể không đủ để thu thập toàn bộ thông tin cần thiết. Đó là lúc Agentic RAG phát huy tác dụng. Thay vì xem việc tìm kiếm chỉ là một bước cố định trong pipeline, hệ thống sử dụng chính LLM như một người điều phối. Mô hình có thể tự phân tích câu hỏi, chia nhỏ thành nhiều truy vấn con, thực hiện nhiều lần tìm kiếm song song, đánh giá kết quả thu được và tiếp tục truy xuất nếu cần.
Nhờ khả năng lập kế hoạch và truy xuất nhiều bước, Agentic Retrieval thường xử lý tốt hơn các câu hỏi dài, nhiều lớp thông tin hoặc đòi hỏi suy luận phức tạp. Tuy nhiên, đổi lại hệ thống cũng phức tạp hơn, tốn nhiều tài nguyên hơn và cần cơ chế orchestration tốt hơn so với Classic RAG.24
Chiến lược tối ưu RAG
Ngay cả khi đã triển khai RAG, hệ thống vẫn có thể gặp hai vấn đề khá phổ biến:25
- Thứ nhất là retrieval noise, tức hệ thống tìm được quá nhiều tài liệu nhưng không phải tài liệu nào cũng thực sự liên quan.
- Thứ hai là context fragmentation, khi thông tin quan trọng bị chia nhỏ thành nhiều đoạn khác nhau, khiến không có đoạn nào đủ ngữ cảnh để trả lời câu hỏi một cách đầy đủ.
Để khắc phục những vấn đề này, các hệ thống RAG hiện đại thường áp dụng thêm nhiều kỹ thuật tối ưu:26
- Re-ranking và Context Compression: Sau khi truy xuất được một danh sách tài liệu, hệ thống sẽ sử dụng thêm một mô hình xếp hạng để đánh giá đâu là những đoạn thực sự hữu ích đối với câu hỏi của người dùng. Một số giải pháp còn tiếp tục loại bỏ những câu hoặc đoạn không cần thiết nhằm giảm số lượng token phải gửi cho LLM. Điều này giúp tăng độ chính xác đồng thời giảm chi phí xử lý.
- Hybrid Search: Thay vì chỉ sử dụng tìm kiếm theo từ khóa hoặc chỉ sử dụng tìm kiếm ngữ nghĩa bằng vector, Hybrid Search kết hợp cả hai phương pháp. Nhờ đó hệ thống vừa tận dụng được khả năng hiểu ngữ nghĩa của vector search, vừa không bỏ sót các thuật ngữ hoặc từ khóa đặc thù.
- Query Optimization/query rewriting: Người dùng không phải lúc nào cũng đặt câu hỏi rõ ràng. Vì vậy, trước khi tìm kiếm, hệ thống có thể tự động viết lại, mở rộng hoặc chia nhỏ truy vấn để tăng khả năng tìm đúng tài liệu. Đây là một kỹ thuật rất phổ biến trong các hệ thống Agentic Retrieval/Agentic RAG hiện đại.
- Chain of Retrieval: Với các câu hỏi cần suy luận nhiều bước, một lần tìm kiếm thường không đủ. Hệ thống có thể lặp lại nhiều vòng theo chu trình: Retrieve → Evaluate → Refine. Nói cách khác, AI sẽ tìm kiếm, đánh giá kết quả, xác định phần thông tin còn thiếu rồi tiếp tục tìm kiếm thêm cho đến khi thu thập đủ dữ liệu để đưa ra câu trả lời đáng tin cậy hơn.
Một vài lưu ý khi triển khai RAG
Nếu phải đúc kết một điều quan trọng nhất khi triển khai RAG, mình sẽ chọn dữ liệu. Rất nhiều người dành phần lớn thời gian để so sánh mô hình nào tốt hơn, vector database nào nhanh hơn hay framework nào hiện đại hơn. Nhưng trên thực tế, chất lượng dữ liệu thường quyết định phần lớn chất lượng của hệ thống RAG. Một kho tri thức lộn xộn, thiếu cấu trúc hoặc lỗi thời sẽ khiến hệ thống truy xuất sai ngay từ đầu. Và khi dữ liệu đầu vào đã sai, LLM gần như không còn cơ hội để tạo ra câu trả lời chính xác. Vì vậy, trước khi nghĩ đến việc tối ưu mô hình, hãy dành thời gian để làm sạch dữ liệu, chuẩn hoá tài liệu và bổ sung metadata phù hợp. Những thông tin tưởng chừng đơn giản như tiêu đề, ngày cập nhật, phân loại tài liệu hay mối quan hệ giữa các nội dung đôi khi lại tạo ra khác biệt rất lớn trong chất lượng truy xuất.
Bên cạnh đó, đừng kỳ vọng xây dựng được một hệ thống RAG hoàn hảo ngay từ lần triển khai đầu tiên. Trong thực tế, RAG là một quá trình tối ưu liên tục. Bạn có thể bắt đầu với một tập dữ liệu nhỏ, theo dõi chất lượng câu trả lời, sau đó điều chỉnh dần chiến lược chunking, embedding, prompt hoặc cách tổ chức dữ liệu. Việc đo lường các chỉ số như độ chính xác, mức độ hài lòng của người dùng hay thời gian phản hồi sẽ giúp bạn hiểu rõ hệ thống đang gặp vấn đề ở đâu.
Một kinh nghiệm khác là đừng phụ thuộc hoàn toàn vào một phương pháp tìm kiếm duy nhất. Nhiều hệ thống hiện đại sử dụng hybrid search để tận dụng điểm mạnh của từng cách tiếp cận. Sau khi truy xuất, kết quả thường được xếp hạng lại hoặc đánh giá mức độ đầy đủ của ngữ cảnh trước khi gửi cho LLM. Điều này giúp giảm đáng kể tình trạng tìm được tài liệu liên quan nhưng lại không đủ thông tin để trả lời câu hỏi.
Chi phí cũng là một yếu tố dễ bị bỏ quên trong giai đoạn thử nghiệm. Mỗi lần truy xuất, embedding hay gọi LLM đều tiêu tốn tài nguyên. Khi hệ thống mở rộng về quy mô, những chi phí này có thể tăng nhanh hơn dự kiến. Vì vậy, việc sử dụng cache augmented generation (CAG), giới hạn số lượng tài liệu được đưa vào ngữ cảnh hoặc lựa chọn mô hình phù hợp với từng bài toán sẽ giúp hệ thống vận hành hiệu quả hơn trong dài hạn.
Cuối cùng, đừng xem RAG đơn thuần là một bài toán về kỹ thuật. Đây thực chất là bài toán của dữ liệu, kiến trúc hệ thống, bảo mật và vận hành. Một hệ thống RAG tốt không chỉ cần kỹ sư AI, mà còn cần sự phối hợp của những người hiểu dữ liệu, hiểu nghiệp vụ và hiểu các yêu cầu về bảo mật. Cũng giống như nhiều hệ thống khác trong doanh nghiệp, thành công của RAG thường đến từ cách các thành phần làm việc cùng nhau, hơn là từ một công nghệ riêng lẻ nào đó.
Tạm kết
Retrieval‑Augmented Generation cũng như những kỹ thuật khác trong mô hình hoạt động của AI, một mình nó sẽ không giải quyết được toàn bộ vấn đề mà AI đang gặp phải. Tuy nhiên, không thể phủ nhận RAG vẫn mang lại hiệu quả nhất định và đang là một trong những thành phần quan trọng trong một hệ thống AI, cho dù là truyền thống hay agentic (tác nhân).
Với tư cách là Product Owner hay bất kỳ ai làm sản phẩm liên quan đến AI, việc hiểu về RAG cũng như những ưu-nhược điểm của nó là rất cần thiết. Để từ đó, bạn có thể biết cách xây dựng chiến lược hợp lý cho việc sử dụng RAG. Và đừng quên rằng, trong quá trình triển khai RAG, đầu tư vào dữ liệu chất lượng, thử nghiệm liên tục và luôn đặt yếu tố bảo mật lên hàng đầu sẽ giúp bạn xây dựng những trải nghiệm AI đáng tin cậy, cập nhật và hướng tới người dùng.
Chúc bạn gặt hái được kết quả tốt đẹp!
Cheers & peace! 🍋 🕊️
Nguồn tham khảo
- https://arxiv.org/html/2005.11401v4 ↩︎
- https://aws.amazon.com/vi/what-is/retrieval-augmented-generation/ ↩︎
- https://www.microsoft.com/en-us/microsoft-cloud/blog/2025/02/04/common-retrieval-augmented-generation-rag-techniques-explained/ ↩︎
- https://research.google/blog/deeper-insights-into-retrieval-augmented-generation-the-role-of-sufficient-context/ ↩︎
- https://www.microsoft.com/en-us/microsoft-cloud/blog/2025/02/04/common-retrieval-augmented-generation-rag-techniques-explained/ ↩︎
- https://docs.cloud.google.com/gemini-enterprise-agent-platform/models/grounding/overview ↩︎
- https://docs.cloud.google.com/gemini-enterprise-agent-platform/build/rag-engine/rag-overview ↩︎
- https://www.ibm.com/think/topics/data-ingestion ↩︎
- https://www.comet.com/site/blog/retrieval-augmented-generation/ ↩︎
- https://www.ibm.com/think/topics/vector-embedding ↩︎
- https://author-ide.skills.network/render?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJtZF9pbnN0cnVjdGlvbnNfdXJsIjoiaHR0cHM6Ly9jZi1jb3Vyc2VzLWRhdGEuczMudXMuY2xvdWQtb2JqZWN0LXN0b3JhZ2UuYXBwZG9tYWluLmNsb3VkL2NTM2VydXFvd196ME9Ga25WZzlaaEEubWQ_dD0xNzU0NTk1NjQwIiwidG9vbF90eXBlIjoiaW5zdHJ1Y3Rpb25hbC1sYWIiLCJhdGxhc19maWxlX2lkIjo0NzE0OSwiYWRtaW4iOmZhbHNlLCJpYXQiOjE3NTc2OTU3MjF9.tUnpbZNu0iJL1KIGUIB55_COJLaQkzxa2gOlvxu8KKw ↩︎
- https://aws.amazon.com/blogs/machine-learning/streamline-rag-applications-with-intelligent-metadata-filtering-using-amazon-bedrock/ ↩︎
- https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking ↩︎
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview?tabs=videos ↩︎
- https://author-ide.skills.network/render?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJtZF9pbnN0cnVjdGlvbnNfdXJsIjoiaHR0cHM6Ly9jZi1jb3Vyc2VzLWRhdGEuczMudXMuY2xvdWQtb2JqZWN0LXN0b3JhZ2UuYXBwZG9tYWluLmNsb3VkL0x0UVFYbmQ2T3U0YlFpTzFycTFGZXcvQ2hlYXRzaGVldCUyMC0lMjBJbnRyb2R1Y3Rpb24lMjB0byUyMFJBRy12MS5tZD90PTE3NDYxMjg2ODEiLCJ0b29sX3R5cGUiOiJpbnN0cnVjdGlvbmFsLWxhYiIsImF0bGFzX2ZpbGVfaWQiOjMwMzY3OCwiYWRtaW4iOmZhbHNlLCJpYXQiOjE3NTc2OTc1MDl9.HOUjrlzz-9qrOXR6zeoiCnDBRgQF0vMguuAJk4XolLg ↩︎
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview?tabs=videos ↩︎
- https://www.microsoft.com/en-us/microsoft-cloud/blog/2025/02/04/common-retrieval-augmented-generation-rag-techniques-explained/ ↩︎
- https://research.google/blog/deeper-insights-into-retrieval-augmented-generation-the-role-of-sufficient-context/ ↩︎
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview?tabs=videos ↩︎
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview?tabs=videos ↩︎
- https://research.google/blog/deeper-insights-into-retrieval-augmented-generation-the-role-of-sufficient-context/ ↩︎
- https://www.comet.com/site/blog/retrieval-augmented-generation/ ↩︎
- https://www.comet.com/site/blog/retrieval-augmented-generation/ ↩︎
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview?tabs=videos ↩︎
- https://www.comet.com/site/blog/retrieval-augmented-generation/ ↩︎
- https://www.comet.com/site/blog/retrieval-augmented-generation/ ↩︎
Leave a Reply
You must be logged in to post a comment.